
Xây dựng real-time analytics dashboards với Postgres và Citus
January 18, 2021Postgres Citus được mở rộng (Scale out) cho một số trường hợp sử dụng khác nhau, cả dưới dạng hệ thống bảng ghi (system of record) và hệ thống tương tác (system of engagement).
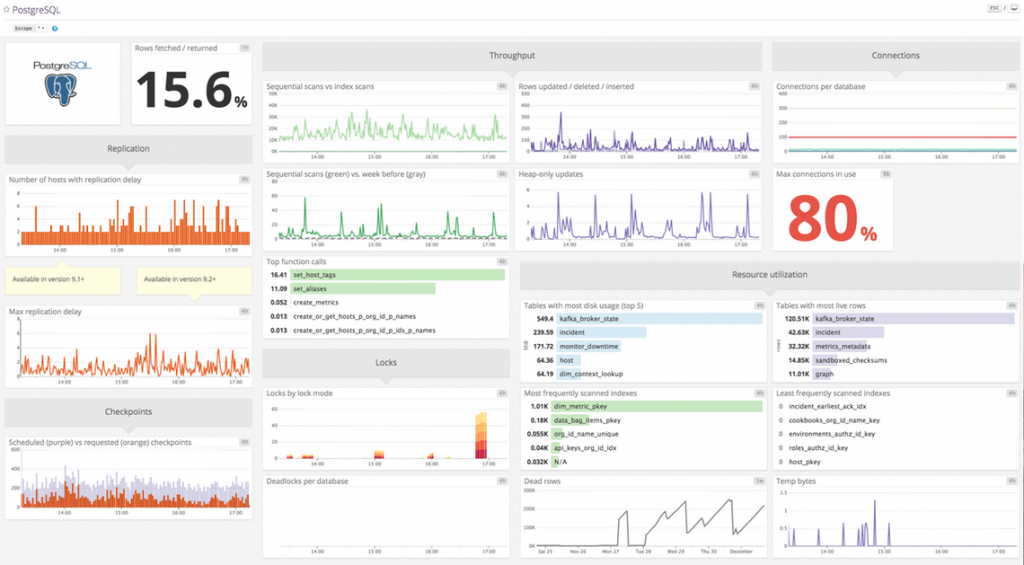
Một trong những trường hợp sử dụng phổ biến ngày này đó là sử dụng vào việc phân tích cơ sở dữ liệu với thời gian thực (real-time analytics dashboards), nó có thể xử lý được hàng triệu khách hàng và hàng tỉ sự kiện trên mỗi ngày.
Citus phù hợp với các loại event dashboards vì khả năng nhập số lượng lớn dữ liệu, thực hiện đồng thời, trộn dữ liệu chưa được kiểm soát với dữ liệu tổng hợp trước và hỗ trợ số lượng lớn người dùng đồng thời. Bạn hình dung Citus có thể giúp bạn nhào nặn những giá trị dữ liệu thô và xử lý chúng trong thời gian thực một cách đồng thời với độ chính xác cao, khả năng hỗ trợ số lượng lớn xử lý đồng thời (CCUs)
Trong bài viết này mình sẽ cùng bạn phân tích và đi dạo quanh một vòng về cách mà Citus hoạt động nhằm xử lý dữ liệu trong thời gian thực như thế nào.
Ingesting data
Bước đầu tiên trong bước xử lý dữ liệu của citus là bước nhập dữ liệu đầu vào. Thông thường để nhập liệu cho một bảng dữ liệu nào đó, ta thường bắt đầu với những dòng đơn (single record). Chẳng có vấn đề gì khi số lượng dữ liệu ít, rồi trong một trường hợp nào đó bạn sẽ phải nhập liệu với một số lượng lớn data vào cùng một bảng, khi đó bạn sẽ dùng bulk insert để đẩy cả một khối lượng lớn dữ liệu vào cơ sở dữ liệu. Chuyện chẳng dừng ở đó, khi bạn vẫn phải nhập liệu một khối lượng dữ liệu lớn vào table nhưng lại với hình thức real-time, nhập liệu một khối dữ liệu mỗi giây. Đến đây sẽ nảy sinh ra một ý tưởng xử lý micro-batching, bạn cứ hiểu đơn giản là việc nhập một khối lượng dữ liệu lớn được xé nhỏ ra và thực hiện chúng song song giống như single record tuy nhiên đơn vị nhập liệu ở đây chính là những gói dữ liệu (packages)
Với \copy tiện ích trong Citus bạn có thể tải số lượng lớn dữ liệu Postgres và nhập hàng triệu sự kiện mỗi giây. \copy là fully transactional và tải và phân phối trên tất cả các node với Citus, làm cho node điều phối Citus của bạn tránh được vấn đề thắt cổ chai khi nhập liệu.
Bạn có thể tìm hiểu thêm về tiện ích \copy tại đây
# faster-bulk-loading-in-postgresql-with-copy
Bạn có các gói dữ liệu, bạn có sự kiện (event) truyền nhận tín hiện, tuy nhiên bạn sẽ phải quản lý các sự kiện đó ra sao. Thật may mắn khi có nhiều framework hỗ trợ giúp bạn xử lý và quản lý các sự kiện theo dạng streaming với những gói packages nhỏ lẻ như Kafka hoặc Kinesis. Điều này sẽ phối hợp hoàn hảo với Citus để giúp bạn nhập liệu với thời gian thực một cách dễ dàng. Bạn lại tiếp tục hình dung những nền tảng như Kafka sẽ giúp bạn xé nhỏ những event thành nhiều những messages nhỏ và truyền tín hiệu đi, quy trình này được xử lý song song và có thể thực hiện trong thời gian thực, tức là cứ sau mỗi x giây thì sự kiện lại được truyền đi với nhiều gói package và nhập liệu vào cơ sở dữ liệu. Điều này giúp bạn tăng năng suất và thời gian nhập liệu sẽ diễn ra một cách nhanh chóng.
Structuring your raw events
Bước tiếp theo sau bước nhập liệu dữ liệu vào database thì để có được những gói package truyền nhận thông qua event thì bạn phải model nó, cấu trúc định hình những gói dữ liệu sự kiện đó tùy theo nhu cầu phân tích dữ liệu của bạn. Bạn có thể hiểu một khối lượng lớn dữ liệu thô chưa được xử lý sẽ bao gồm những trường những cột mà bạn sẽ không sử dụng đến, bạn chỉ cần những trường đã được tính toán xử lý và nhằm mục đích phân tích dữ liệu của bạn thì bạn không thể nào giữ nguyên cả một gói tập tin dữ liệu thô như vậy để truyền đi, điều này là không cần thiết và tốn rất nhiều chi phí băng thông truyền nhận. Vậy nên việc chuyển hóa dữ liệu thô thành những dữ liệu tinh đáp ứng cho nhu cầu của bạn là điều bạn phải làm. Và để có được một model gói dữ liệu như vậy thì bạn phải định nghĩa chúng.
CREATE TABLE events(
id bigint,
timestamp timestamp,
customer_id bigint,
event_type varchar,
country varchar,
browser varchar,
device_id bigint,
session_id bigint
);
SELECT create_distributed_table('events','customer_id');Rolling up your data
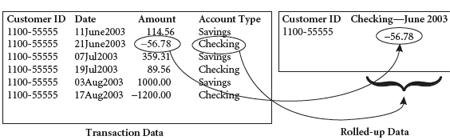
Như mô tả ở bước trên khi bạn xử lý từ dữ liệu thô sang dữ liệu tinh nhằm phục vụ cho mục đích phân tích dữ liệu của bạn thì đó chính là rollups data. Thuật ngữ này là được sử dụng khá nhiều trong phân tích cơ sở dữ liệu, tuy nhiên với Citus bạn có thể hiểu thêm nó sẽ cuộn tập dữ liệu lớn của bạn lên như kiểu quét toàn bộ các dòng và lọc chúng, nhặt chúng ra một nơi khác, và quá trình này được xử lý định thời (interval) có thể là 5 phút, 1 tiếng, 1 ngày, 1 tuần hay 1 tháng một lần phát tín hiệu rolling up data.
CREATE TABLE rollup_events_5min (
customer_id bigint,
event_type varchar,
country varchar,
browser varchar,
minute timestamptz,
event_count bigint,
device_distinct_count hll,
session_distinct_count hll
);
CREATE UNIQUE INDEX rollup_events_5min_unique_idx ON rollup_events_5min(customer_id,event_type,country,browser,minute);
SELECT create_distributed_table('rollup_events_5min','customer_id');
CREATE TABLE rollup_events_1hr (
customer_id bigint,
event_type varchar,
country varchar,
browser varchar,
hour timestamptz,
event_count bigint,
device_distinct_count hll,
session_distinct_count hll
);
CREATE UNIQUE INDEX rollup_events_1hr_unique_idx ON rollup_events_1hr(customer_id,event_type,country,browser,hour);
SELECT create_distributed_table('rollup_events_1hr','customer_id');Việc rollups này đối với Citus có một thuật toán riêng để xử lý cách quét dữ liệu như thế nào sao cho hợp lý và tối ưu nhất có thể. Vì ở đây, bài toán đặt ra là bạn phải xử lý một tập hợp dữ liệu lớn, rất rất lớn, nên vấn đề thời gian quét từng record dữ liệu không phải là vấn đề đơn giản và dễ dàng. Thuật toán này mang tên HypperLogLog (HLL).
Bạn đọc có thể tham khảo tại đây
# efficient-rollup-with-hyperloglog-on-postgres

Quay lại vấn đề việc tổ chức các gói dữ liệu như thế nào là phù hợp, trong ví dụ trên thì mình chỉ để các thông tin được chọn lọc như customer_id, event_type, country, browser, minute/hour. Hay những thông số mang tính thống kê như event_count, device_distinct_count, session_distinct_count…
Vấn đề ở đây là bạn phải phân tích cấu trúc bảng thô như thế nào, và cấu trúc bảng mà bạn cần để phân tích dữ liệu ra sao, từ đó tổ chức các gói packages sao cho phù hợp nhất. Bạn cũng có thể tạo nhiều bảng nhằm mục đích rollups thuận tiện hơn và giúp bạn truy vấn sau khi phân tích được tốt hơn.
Đừng dại khi bạn tạo một gói dữ liệu dùng để phân tích giống hệt như bảng dữ liệu thô nhé!
Một vấn đề nữa là vấn đề kích thước nén gói package sao cho phù hợp. Do vấn đề này ảnh hưởng tới vấn đề truyền tải băng thông dữ liệu nên việc setting sao cho phù hợp là điều cần phải quan tâm. Tốt nhất, bạn nên chọn kích thước mà bạn có được mức nén phù hợp (> 5-10x) so với các bảng thô. Đôi khi còn tùy thuộc vào khách hàng và kinh nghiệm xử lý dữ liệu nữa, nhưng thường thấy thì cường độ nén sau khi rollups tới 100 lần hoặc 1000 lần là phù hợp.
Lưu ý:
Đối với truy vấn rollups bạn có thể thực hiện một truy vấn INSERT INTO… SELECT sẽ chạy trên tất cả các nodes trong cluster dưới hình thước chạy song song, bất đồng bộ, điều này giúp tăng tốc độ quá trình xử lý quét dữ liệu mà Citus hỗ trợ. Ngoài ra bạn có thể lợi dụng các bảng được phân chia nằm trên các nodes được sharding với key hoặc tenant. Điều này ít nhiều giúp bạn tăng tốc độ truy vấn và rollup nhanh hơn.
Dưới đây là một định nghĩa function rollups với định thời 5 phút và một tiếng, bạn có thể tham khảo:
CREATE OR REPLACE FUNCTION compute_rollups_every_5min(start_time timestamptz, end_time timestamptz) RETURNS void LANGUAGE PLPGSQL AS $function$
BEGIN
RAISE NOTICE 'Computing 5min rollups from % to % (excluded)', start_time, end_time;
RAISE NOTICE 'Aggregating data into 5 min rollup table';
INSERT INTO rollup_events_5min
SELECT customer_id,
event_type,
country,
browser,
date_trunc('seconds', (event_time - timestamptz 'epoch') / 300) * 300 + timestamptz 'epoch' AS minute,
count(*) as event_count,
hll_add_agg(hll_hash_bigint(device_id)) as device_distinct_count,
hll_add_agg(hll_hash_bigint(session_id)) as session_distinct_count
FROM events WHERE event_time >= start_time AND event_time <= end_time
GROUP BY
customer_id,
event_type,
country,
browser,
minute
ON CONFLICT (customer_id,event_type,country,browser,minute)
DO UPDATE
SET
event_count = rollup_events_5min.event_count + excluded.event_count,
device_distinct_count = rollup_events_5min.device_distinct_count || excluded.device_distinct_count,
session_distinct_count = rollup_events_5min.session_distinct_count || excluded.session_distinct_count;
RAISE NOTICE 'Aggregating/Upserting into 1 hr rollup table';
INSERT INTO rollup_events_1hr
SELECT customer_id,
event_type,
country,
browser,
date_trunc('hour', event_time) as hour,
count(*) as event_count,
hll_add_agg(hll_hash_bigint(device_id)) as device_distinct_count,
hll_add_agg(hll_hash_bigint(session_id)) as session_distinct_count
FROM events WHERE event_time >= start_time AND event_time <= end_time
GROUP BY
customer_id,
event_type,
country,
browser,
hour
ON CONFLICT (customer_id,event_type,country,browser,hour)
DO UPDATE
SET
event_count = rollup_events_1hr.event_count+excluded.event_count,
device_distinct_count = rollup_events_1hr.device_distinct_count || excluded.device_distinct_count,
session_distinct_count = rollup_events_1hr.session_distinct_count || excluded.session_distinct_count;
END;
$function$;Sau khi bạn định nghĩa function rollups xong xuôi thì giờ đây hãy thử kích hoạt nó, và tại thời điểm kích hoạt thì Citus sẽ tự động rollup định thời theo 5 phút hoặc một tiếng tùy theo lời gọi kích hoạt của bạn.
SELECT compute_rollups_every_5min(now()-interval '5 minutes', now());Automating your rollups
Vấn đề tự động hóa xử lý rollups theo hình thức định thời bên trên. Có thể sẽ chỉ phù hợp cho một số yêu cầu đặt ra với thời gian thực và lượng dữ liệu thay đổi liên tục. Tuy nhiên nếu cơ sở dữ liệu của bạn chẳng có nhiều tài nguyên thì bạn nên nghĩ theo hướng xử lý lên lịch chạy. Ví dụ thay vì 5 phút bạn chạy rollups một lần thì bạn có thể set thời gian là cứ 12 giờ đêm thì lại thực hiện rollups. Điều này giúp bạn giảm được chi phí tài nguyên và số lần event được phát ra không cần thiết khi dự liệu của bạn 5 phút sau chẳng khác gì so với 5 phút trước thì việc bạn rollups là vô nghĩa.
Bạn đọc có thể tham khảo thêm cách tạo schedule với cron job để lên lịch chạy rollups tại đây:
# pgcron-run-periodic-jobs-in-postgres
Querying the real-time events dashboard
Với vấn đề hiệu năng và thực hiện song song trong bước nhập liệu và bước rollups trong Citus đã giúp bạn tối ưu hóa hệ thống phân tích dữ liệu trong thời gian thực rồi, thì vấn đề truy vấn dữ liệu tinh ở bước này cũng sẽ được thực hiện một cách song song và hiệu quả. Do bước xử lý chuyển đổi dữ liệu thô sang dữ liệu tinh dựa trên yêu cầu phân tích dữ liệu của bạn sẽ ảnh hướng đến quá trình truy vấn dữ liệu đã được xử lý và hiển thị này. Đơn cử như vấn để đếm, lọc, và sắp xếp các giá trị, một khi bạn xử lý chuyển đổi dữ liệu tốt thì vấn đề truy vấn dữ liệu tinh này sẽ vô cùng hiệu quả và đơn giản.
Dưới đây là một vài câu lệnh truy vấn lấy dữ liệu lên để hiển thị, chú ý rằng do Citus của bạn đã được setup real-time xử lý rollups và kết hợp với event truyền nhận trong thời gian thực thì vấn đề xử lý truy vấn này cũng được thực hiện real-time và song song tương tự:
SELECT sum(event_count), hll_cardinality(hll_union_agg(device_distinct_count))
FROM rollup_events_5min
WHERE minute >=now()-interval '5 minutes' AND minute <=now() AND customer_id=1;
SELECT sum(event_count), hll_cardinality(hll_union_agg(device_distinct_count))
FROM rollup_events_1hr
WHERE hour >=date_trunc('day',now())-interval '7 days' AND hour <=now() AND customer_id=1;
SELECT hour, sum(event_count) event_count, hll_cardinality(hll_union_agg(device_distinct_count)) device_count, hll_cardinality(hll_union_agg(session_distinct_count)) session_count
FROM rollup_events_1hr
WHERE hour >=date_trunc('day',now())-interval '2 days' AND hour <=now() AND customer_id=1
GROUP BY hour;Được rồi, giờ hãy thử trải nghiệm tính năng khá hay ho này đối với Citus Data nhé!

[…] ← Previous Next → […]