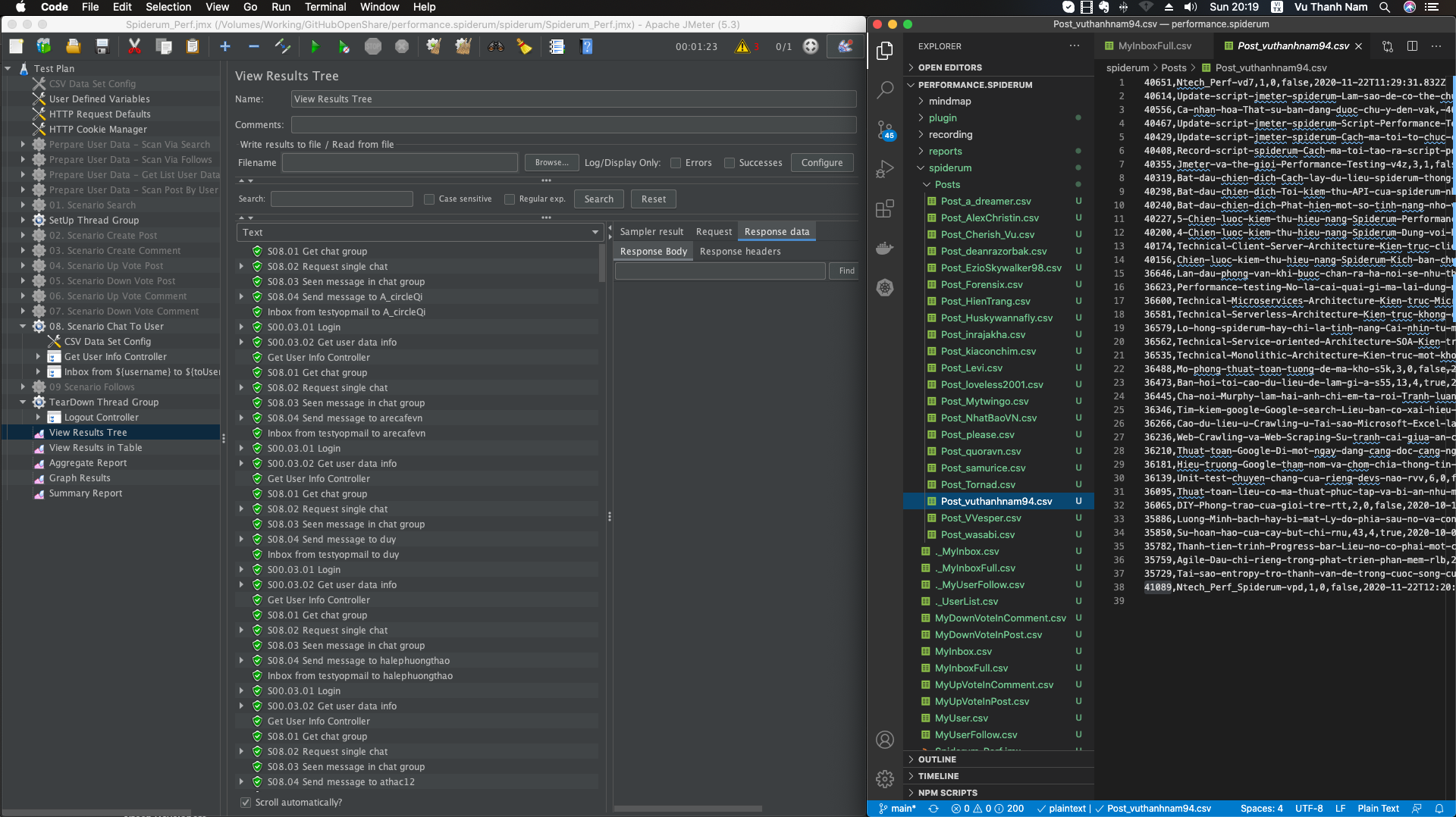
#13 Update script jmeter spiderum – Làm sao để có thể chuẩn bị data cho cả triệu CCUs
November 21, 2020Trước đó mình đã đi dạo một vòng các api tìm kiếm người dùng khi thực hiện kiểm thử api. Từ đó mình thấy có thể lợi dụng chức năng tìm kiếm để có thể tạo dữ liệu đầu vào cho chiến dịch kiểm thử lần này.
Bài viết trước mình có giới thiệu cho các bạn mấy cách để Extract data(bóc tách dữ liệu) trong jmeter, bạn có thể đọc lại tại đây
# http://blog.ntechdevelopers.com/update-script-jmeter-spiderum-script-performance-test-khong-phai-chi-record-la-xong-con-nhieu-thu-hay-ho-lam/
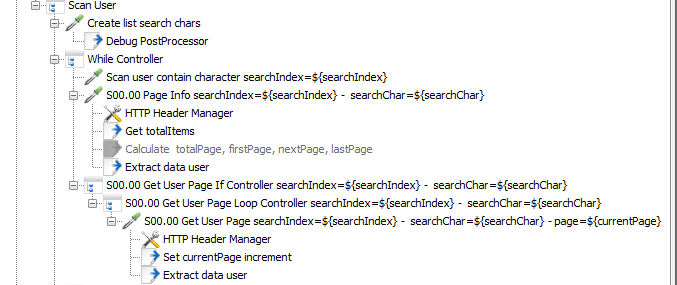
Ở bài viết này mình sẽ giới thiệu cách lấy lượng lớn dữ liệu thông qua Loop Thread Group và Loop Controller (While, Foreach, If)
Đầu tiên mình phải đề cập lại một lần nữa là mình không thuộc đội ngũ phát triển spiderum nên mình không hề biết cơ sở dữ liệu và cách tổ chức website của spiderum trước đó. Tất cả những dữ liệu này mình có được đều dựa trên việc mình tìm tòi thông qua GUI của website từ đó thu thập các endpoint api để phục vụ cho chiến dịch kiểm thử lần này.
Được rồi bắt đầu nhé!
Điều đầu tiên mình tìm hiểu được thành viên trong spiderum chia thành 2 dạng: topUser (những thành viên trong danh mục thành viên nổi bật) và nguoi-dung (những thành viên thông thường khác)Mỗi thành viên trong danh sách topUser được cấp một domain (tên miền) riêng, ví dụ vietanhtran.spiderum.com, cái này gọi là phân biệt chủng tộc, phân biệt giai cấp. Cũng phải thôi vì sub-domain (tên miền từ domain mua ban đầu) sẽ có số lượng có hạn nên chỉ dành cho team nội bộ spiderum thôi.
2020-11-20 18:02:57,842 INFO o.a.j.u.BeanShellTestElement: Log domain: http://huskywannafly.spiderum.com
2020-11-20 18:02:57,848 INFO o.a.j.u.BeanShellTestElement: Log domain: http://vietanhtran.spiderum.com
2020-11-20 18:02:57,855 INFO o.a.j.u.BeanShellTestElement: Log domain: http://adreamer.spiderum.com
2020-11-20 18:02:57,861 INFO o.a.j.u.BeanShellTestElement: Log domain: http://hexpion.spiderum.com
2020-11-20 18:02:57,867 INFO o.a.j.u.BeanShellTestElement: Log domain: http://wasabi.spiderum.com
2020-11-20 18:02:57,878 INFO o.a.j.u.BeanShellTestElement: Log domain: http://elbe040.spiderum.com
2020-11-20 18:02:57,884 INFO o.a.j.u.BeanShellTestElement: Log domain: http://samurice.spiderum.com
2020-11-20 18:02:57,890 INFO o.a.j.u.BeanShellTestElement: Log domain: http://cherishvu.spiderum.com
2020-11-20 18:02:57,903 INFO o.a.j.u.BeanShellTestElement: Log domain: http://ngalevi.spiderum.com
2020-11-20 18:02:57,909 INFO o.a.j.u.BeanShellTestElement: Log domain: http://nguyenbaotrung.spiderum.com
2020-11-20 18:02:57,915 INFO o.a.j.u.BeanShellTestElement: Log domain: http://loveless.spiderum.com
2020-11-20 18:02:57,921 INFO o.a.j.u.BeanShellTestElement: Log domain: http://quoravn.spiderum.com
2020-11-20 18:02:57,933 INFO o.a.j.u.BeanShellTestElement: Log domain: http://alexvu.spiderum.com
2020-11-20 18:02:57,940 INFO o.a.j.u.BeanShellTestElement: Log domain: http://hainguyen.spiderum.com
2020-11-20 18:02:57,946 INFO o.a.j.u.BeanShellTestElement: Log domain: http://vvesper.spiderum.com
2020-11-20 18:02:57,966 INFO o.a.j.u.BeanShellTestElement: Log domain: http://nhatbaovn.spiderum.com
2020-11-20 18:02:57,979 INFO o.a.j.u.BeanShellTestElement: Log domain: http://limitless.spiderum.com
2020-11-20 18:02:57,985 INFO o.a.j.u.BeanShellTestElement: Log domain: http://tornad.spiderum.com
2020-11-20 18:02:57,991 INFO o.a.j.u.BeanShellTestElement: Log domain: http://hientrang.spiderum.comVấn đề chia domain khiến mình cũng gặp khó khăn trong việc lấy dữ liệu những thành viên đó, vì cơ bản thì nó không theo quy tắc và mỗi trang trong sub-domain trên lại có bố cục và cách tổ chức trang khác nhau (Customization)
Do đó mình sẽ chia thành 2 ThreadGroup scan data đó là “Scan Top User” và “Scan User”. Hiện tại TopUser chỉ có 20 thành viên trong cùng một trang nên rất dễ dạng có thể lấy được thông tin, chỉ cần gọi tới end-point “/api/v2/user/getTopUsers” và bóc tách dữ liệu từ response trả về thôi, không cần loop gì nhiều.
Vấn đề phát sinh đầu tiên là nếu mình dựa vào chức năng tìm kiếm (search) người dùng để tìm những thành viên khác của spiderum thì mỗi lần search theo một ký tự cố định nào đó thì mình chỉ có thể có được những thành viên có chứa ký tự search đó mà thôi.
Vậy là mình nẩy ra ý tưởng mình có 1 chuỗi tất cả các ký tự search_string=”abcdefghijklmnopqrstuvwxyz0123456789″ thì nếu mình băm nhỏ các ký tự từ a đến z và từ 0 tới 9 sau đó lấy ký tự đó để tìm kiếm thì số lượng người dùng mình có được sẽ gần như hết tất cả các thành viên trên spiderum.
Triển khai ý tưởng này mình có đoạn code bên dưới được viết bằng ngôn ngữ java thông qua BeanShell Sampler (cái này là gì thì bạn có thể đọc lại bài viết trước nhé!
log.info("Begin scan user...");
String searchString = vars.get("search_string");
ArrayList searchChars = new ArrayList();
for(int i = 0, n = searchString.length() ; i < n ; i++) {
char c = searchString.charAt(i);
searchChars.add(c);
}
int searchSize = searchChars.size();
vars.put("searchIndex", 0 + "");
vars.put("searchSize", searchSize + "");
vars.put("searchChars", searchChars + "");Bạn thấy đó, chỉ cần một đoạn code nhỏ mình đã cắt nhỏ chuỗi trên thành các ký tự để tìm kiếm. Sau đó mình đẩy thông tin trên vào biết tương ứng để sử dụng vòng lặp tìm kiếm phía sau.
Vấn đề phát sinh tiếp theo đó là phân trang, một vòng lặp hiện tại thì mình chỉ tìm kiếm một ký tự a chẳng hạn, khi đó nó ra 6 trang chứa 105 thành viên có chứa chữ a tại thời điểm hiện tại. Vậy làm sao mình có thể biết có bao nhiêu trang và có bao nhiêu thành viên trong một trang, khi đó phải lặp bao nhiêu lần để có được dữ liệu data chỉ cho mỗi ký tự a.
Vấn đề được giải quyết khi mình gọi api đầu tiên với ký tự đầu tiên trong chuỗi cắt bên trên (ở trường hợp này sẽ là chữ a đầu tiên) và trang thứ nhất (vì dù ít data nhất hoặc không có data thì cũng hiển thị trang đầu tiên)
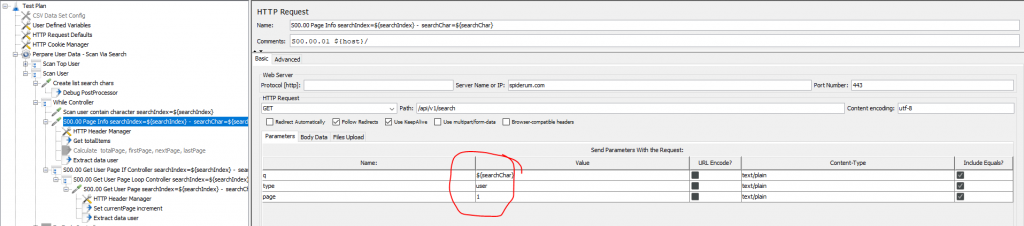
Khi đó mình sẽ có được dữ liệu ở trang đầu tiên, đồng thời mình tính được tổng các thành phần như tổng số trang, tổng số phần tử trong 1, trang kế tiếp, trang đầu tiên từ tổng số phần tử mà api đầu tiên trả về sau đó gán những thông tin đó vào biến.
Thế là mình đã có các biến để truyền vào vòng lặp lấy thông tin của tất cả các trang.
JSONObject store = (JSONObject) parser.parse(data);
int totalItems = (int) store.get("totalItems");
log.info("Log totalItems: " + totalItems);
JSONArray items = (JSONArray) store.get("items");
int totalItemsInPage = (int) items.size();
log.info("Log totalItemsInPage: " + totalItemsInPage);
log.info("Log items: " + items);
// Calulate page
int totalPage = 0;
int firstPage = 1;
int nextPage = 0;
int currentPage = 1;
if (totalItems > 0 ) {
totalPage = totalItems/totalItemsInPage;
if ((totalItems % totalItemsInPage) > 0) {
totalPage += 1;
nextPage = firstPage + 1;
}
}
vars.put("totalPage", totalPage + "");
vars.put("firstPage", firstPage + "");
vars.put("nextPage", nextPage + "");
vars.put("lastPage", totalPage + "");
vars.put("currentPage", currentPage + "");Có được các thông tin thì mình dùng If Controller và Loop Controller để có thể lặp các trang lấy được tất cả các user có chứa chữ a bên trên. Vòng lặp này sẽ được lồng vào lòng lăp 36 lần của 36 ký tự bên trên mình đã cắt ra được.
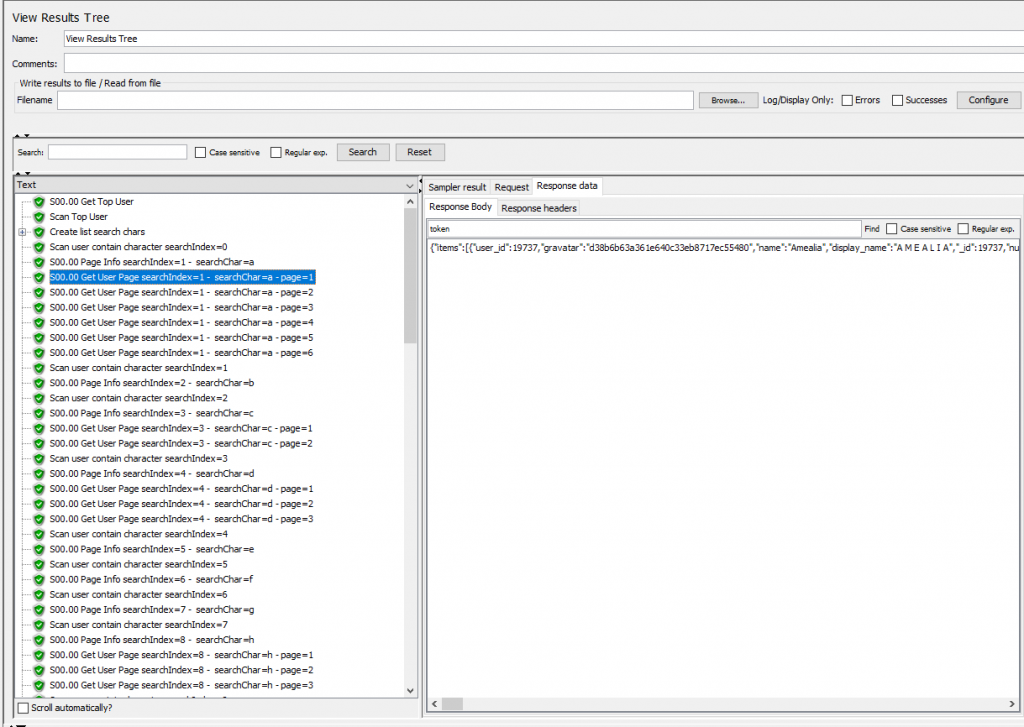
Đến đây mình đã có được response của tất cả các user. Vấn đề bây giờ là bóc tách chúng và lưu nó vào file. Cái này code java thì khá đơn giản thôi. Chỉ có một lưu ý là trường hợp trùng (duplidate) khi tìm kiểm. Ví dụ chữ “n” vừa nằm trong user “ntech” vừa nằm trong Huskywannafly vậy khi mình search chữ “h” nó cũng ra 2 user này mà mình search chữ “n” cũng ra 2 user này. Vậy nên mình sẽ phải kiểm tra xem user đó mình đã quét qua chưa. Nếu chưa quét qua thì mình lưu xuống file, nếu quét qua rồi thì mình bỏ qua chẳng làm gì hết
// Export csv
for (Object item : items) {
JSONObject item = (JSONObject) item;
int userId = (int) item.get("user_id");
String name = (String) item.get("name");
String newData = userId + "," + name;
// Check duplicate data
boolean isDuplicate = oldData.contains(newData);
if(!isDuplicate){
log.info("Log user: " + newData);
writer.write( userId + "," + name);
writer.write(System.getProperty("line.separator"));
}
else{
log.info("Log duplidate data. " + newData);
}
}Không đơn giản chỉ đến đây mà mình có được hết tất cả các thông tin của thành viên. Vấn đề này xảy ra có lẽ là tính năng của spiderum. Ví dụ mình search chữ “test” thì nó không ra user mình cần, mà mình search chữ “testyopmail” thì mới hiển thị ra, mặc dù chữ testyopmail chứa chứ test.
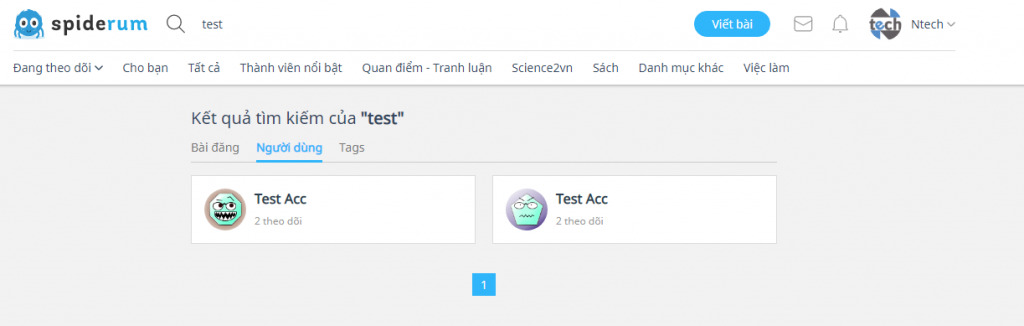
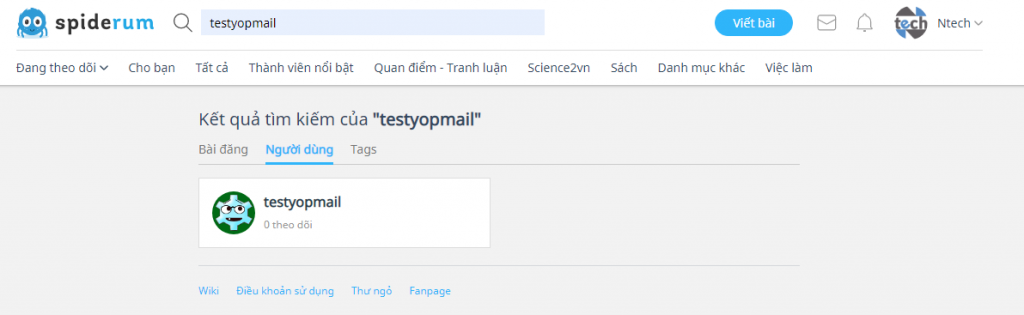
Bạn hình dung mình cắt chữ “a” tìm kiếm không thấy user mà bắt buộc tìm kiểm chữ “ab” mới thấy user. Tức là tổ hợp của 36 ký tự “abcdefghijklmnopqrstuvwxyz0123456789”, như vậy không ổn rồi, nó sẽ sót một số lượng user lớn.
Vậy là mình phải thêm một giải pháp khác để quét lượng user còn sót bằng cách lấy qua thành viên được theo dõi (followers) và đi theo dõi thành viên viên khác (followings) để có thể lấy tiếp lượng user. Nếu tìm người theo dõi của một user bất kỳ bạn tìm kiếm được thì bạn không cần phải đăng nhập. Còn nếu bạn được người khác theo dõi và cần lấy thông tin những người theo dõi đó thì bạn cần phải đăng nhập. Đến đây mình phải tách thành 2 kịch bản followings và followers.
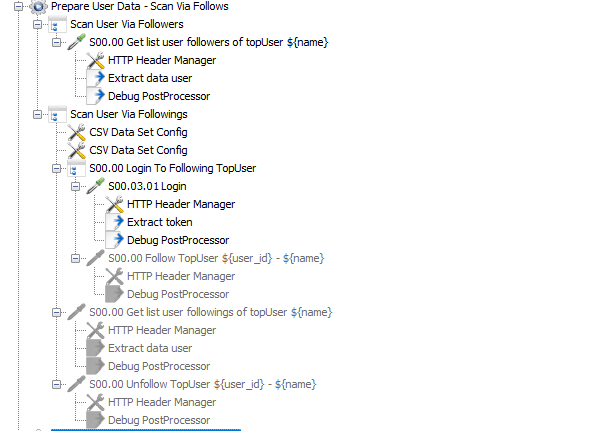
Kết quả cuối cùng thì mình có 2 file csv chứa thông tin của các user mà mình scan được thuộc 2 loại topUser và nguoi-dung. Ở đây mình chỉ lấy thông tin là user_id và name (username) vì các bước sau mình chỉ dùng đến 2 thông tin này. Mình sẽ có 1 ThreadGroup khác lấy full thông tin người dùng để gửi tin nhắn ở bài viết sau.
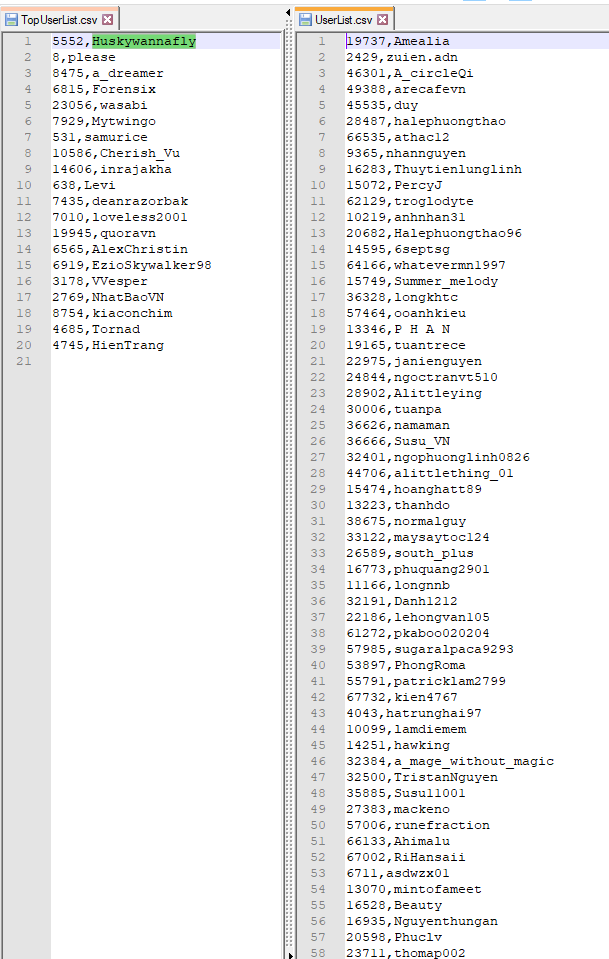
Vậy bạn đặt câu hỏi dùng 2 file csv này để làm gì?
Mình có nói ở trên là mình dùng để cho các kịch bản phía sau với số lượng CCUs bằng số lượng user mà mình quét được.
Nếu bạn đọc loạt bài viết này từ đầu thì bạn thấy mình để CSV Data Set Configlại sau cùng chưa đề cập đến.
CSV Data Set Config là một trong những element cấu hình quan trọng trong Jmeter. Nó được sử dụng trong việc tham số hóa trong Jmeter Test Plan.
Tham số hóa trong Jmeter là quá trình thực hiện Test Plan với nhiều bộ người dùng Input Data. Bằng cách thực hiện tham số hóa, chúng ta tổng quát thao tác nhập dữ liệu cho nhiều người dùng.
Sử dụng CSV Data Set Config để đọc các giá trị từ file CSV, lưu trữ chúng vào các biến được định nghĩa và sử dụng trong suốt quá trình kiểm thử với vai trò như Test Data.
– FileName: Tên tệp chính xác (có đuôi .csv) chứa dữ liệu kiểm thử để thực thi và được đặt ở cùng vị trí với Jmeter script.
– Variable Names: danh sách tất cả các tên biến (được phân tách bằng dấu phẩy) theo cùng thứ tự như được mô tả trong file CSV. Giữ trường này trống và jmeter sẽ lấy hàng đầu tiên từ tệp csv làm tên biến cho mỗi cột.
– Delimiter: được sử dụng để tách từng bản ghi trong tệp csv. Bạn cần đảm bảo xác định tên biến theo thứ tự chính xác khi bạn cung cấp giá trị trong file csv.
– Allow quoted data?: Nếu được bật, thì các giá trị có thể được đặt trong ”- dấu ngoặc kép – cho phép các giá trị chứa dấu phân cách.
– Recycle on EOF?: Nếu số lượng thread lớn hơn số lượng Test Data, bạn có muốn tiếp tục thực hiện kiểm thử bằng cách quay trở lại đọc từ đầu không?
– Stop thread on EOF?: Nếu chọn “Set”, khi chạy đến EOF sẽ khiến cho thread bị dừng lại.
– Sharing mode: Tại đây bạn có thể định nghĩa hành vi chia sẻ của file CSV. Mặc định sẽ chọn là “All threads”
– All threads: Nếu trong script của bạn có nhiều hơn 1 element CSV Data Set Config cùng tham chiếu đến 1 file thì CSV Data Set Config kế tiếp sẽ tiếp tục đọc CSV File đã được mở từ CSV Data Set Config trước.
+ Current Thread Group: Nếu trong script của bạn có nhiều hơn 1 element CSV Data Set Config cùng tham chiếu đến 1 file thì CSV Data Set Config kế tiếp sẽ mở lại csv file cho từng trhread group
+ Current Thread: Mỗi file csv được mở riêng biệt cho từng thread khi chọn option này.
Kết hợp CSV Data Set Config với file csv bên trên thì mình có thể quét được tất cả các bài viết và thông tin chi tiết của tất cả các thành viên.
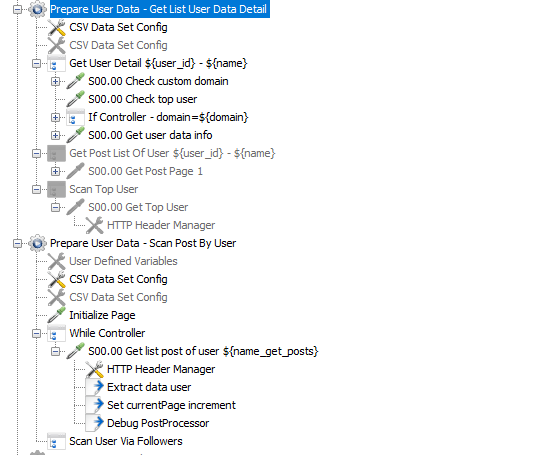
Các bài viết của topUser thường nhiều và chất lượng nên sau khi scan thì mình đặt tên file và thư mục riêng nhằm cho kịch bản upvote và bình luận bài viết. Tương tự thì mình cũng chỉ cần thông tin cơ bản như post_id và slug mà thôi
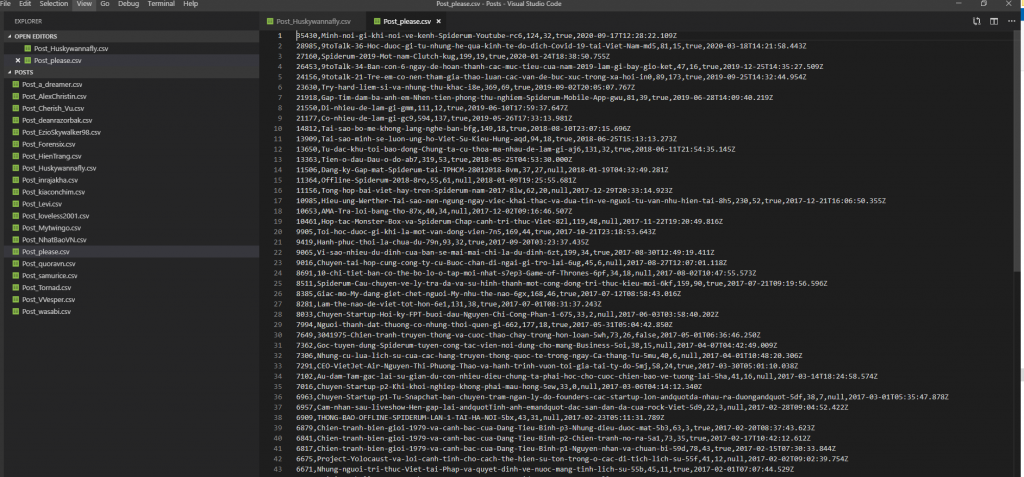
Đến đây bạn có thể hiểu mình làm thể nào để chuẩn bị dữ liệu kiểm thử với số lượng lớn rồi đúng không.
Bên cạnh đó mình vẫn theo cách này để tạo ra các file csv tương ứng với từng kịch bản cho chiến dịch kiểm thử hiệu năng lần này.
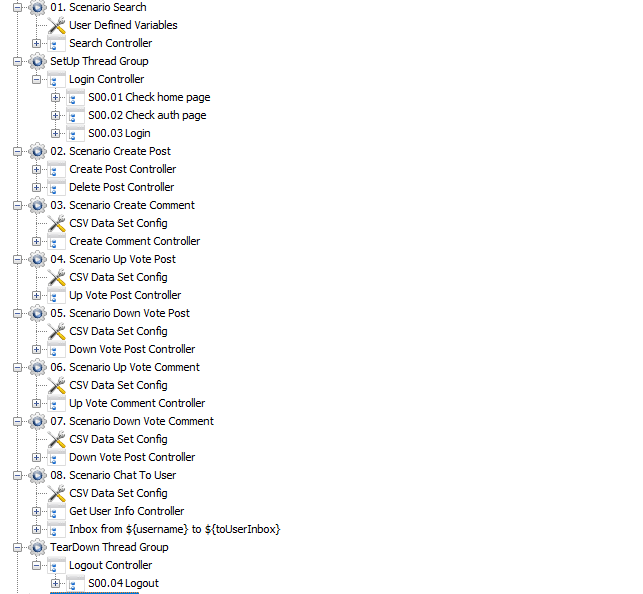
Mình sẽ upload tất cả các script cũng như dữ liệu này lên github, nếu bạn nào có hứng thú với performance testing thì có thể kéo về nghiên cứu hoặc liên hệ mình nếu có bất cứ câu hỏi gì.
Thân ái chào các bạn và hẹn gặp lại vào cuối tuần này mình sẽ bắt đầu thực hiện chạy performance test và xuất report báo cáo ở bài viết tới!
Đợi nhé!