
Hiểu về Sharding trong Citus Data
January 11, 2021Bài viết trước trong phần giới thiệu về Citus Data mình có nói đến một kỹ thuật Sharding. Bạn có thể đọc lại tài đây
# http://blog.ntechdevelopers.com/citus-data-phai-chang-ban-co-nen-su-dung-no-hay-khong/
Ở bài viết này mình sẽ đi sâu hơn về Sharding là gì và giúp bạn hiểu rõ tại sao và khi nào nên sử dụng Sharding.Bắt đầu thôi!
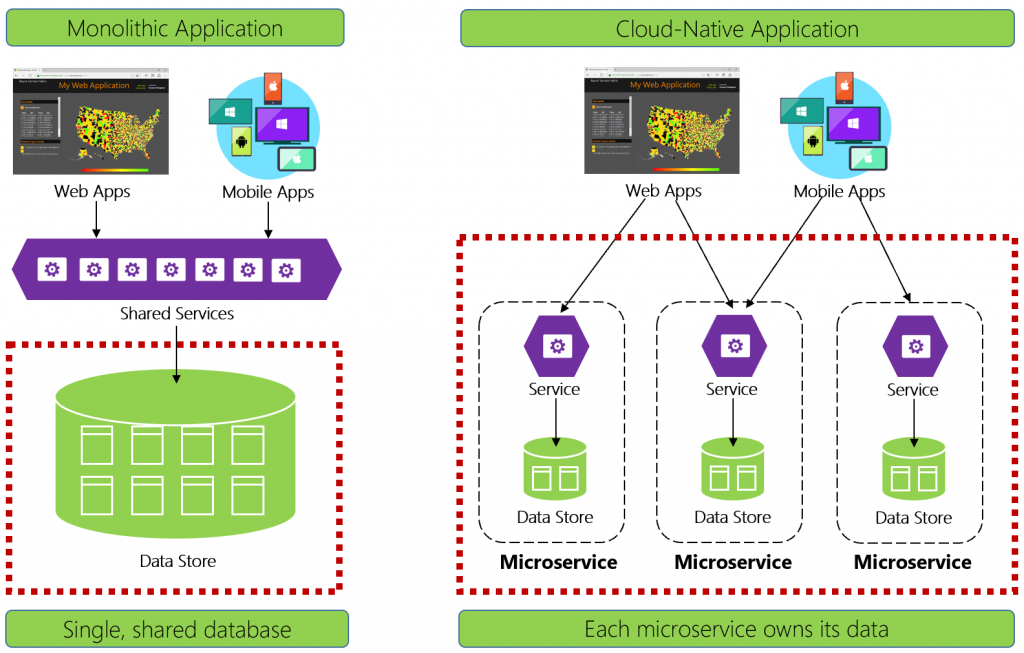
Trước khi đi vào sharding là gì thì các bạn hãy cùng mình tìm hiểu thử tại sao lại sinh ra sharding. Vấn đề được đặt ra ở đây là từ trước đó việc mô hình monolithic phát triển một ứng dụng thì sẽ sử dụng một database duy nhất để lưu trữ cơ sở dữ liệu. Nhưng rồi một ngày hệ thống càng ngày càng lớn, dữ liệu càng ngày càng nhiều khiến đội ngũ phát triển ứng dụng phải đau đầu suy nghĩ cách mở rộng cơ sở dữ liệu để chứa nhiều hơn và tốt hơn. Đến đây chúng ta có 2 cách để mở rộng hệ thống cũng như cơ sở dữ liệu, một là scale up, hai là scale out
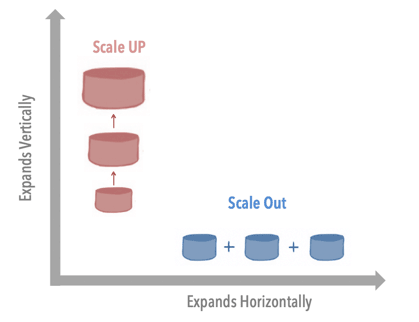
Scale up bạn có thể mở rộng một cách nhanh chóng và không tốn quá nhiều chi phí vào đội ngũ phát triển, nó chỉ đơn thuần là bạn mở rộng cấu hình từ 1x lên 5x hoặc 10x mà thôi. Nếu bạn có 1 máy chủ thì nâng cấp ổ đĩa, cpu, ram,… Nếu bạn dùng cloud thì lại càng dễ dàng khi chỉ đổi gói sử dụng lớn hơn, tất nhiên là chi phí sẽ lớn lên. Tuy nhiên bạn hiểu rằng scale up rồi cũng có ngày bạn gặp giới hạn về độ lớn, ngày xưa 1 thẻ nhớ 125MB cho 1 chiếc điện thoại cùi bắp bạn cảm thấy đủ, nhưng rồi phát triển dần thì giờ đâu 125GB bạn cũng vẫn thấy thiếu. Giờ đây thì nó có thể lên đến vài trăm TB nhưng nó cũng chỉ là nhất thời nếu dữ liệu của bạn bùng nổ thì nó cũng không thể nào chứa được.
Scale out thì bạn lại mở rộng theo chiều ngang điều này giống như bạn chỉ cộng những gợi dây ngắn lại thành một sợi dây dài tùy theo mục đích của bạn. Độ dài của sợi dây chính vì nó là những đoạn ngắn nối lại nên việc bạn mở rộng bao nhiêu là không giới hạn. Mặt khác thì bạn cũng có thể tháo bớt đoạn dây ra nếu thời điểm đó không sử dụng hết tài nguyên. Điều này tránh việc lãng phí tài nguyên ngắn hạn.
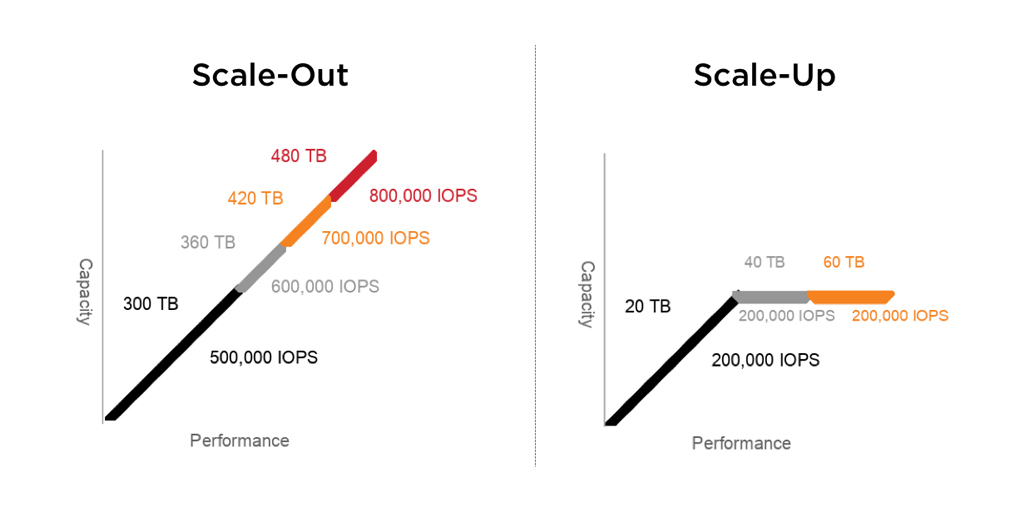
Vậy tại sao bài viết về sharding mà mình lại đề cập tới Scale dữ liệu. Đơn giản rằng khi bạn scale up bạn vẫn không quan tâm tới việc chia cắt dữ liệu sao, vì dù sao thì nó cũng nằm trên cùng một node, một vùng nhớ. Nhưng với scale out thì bạn cần phải quan tâm đến việc chia dữ liệu trong từng đoạn dây nhỏ kia để làm thế nào khi nối lại thành một sợi dây lớn nó vẫn hoạt động trơn tru. Mỗi sợi dây nối vậy được gọi là một node.
Vấn đề của bạn là việc chia tách dữ liệu trên các node sao cho hợp lý.
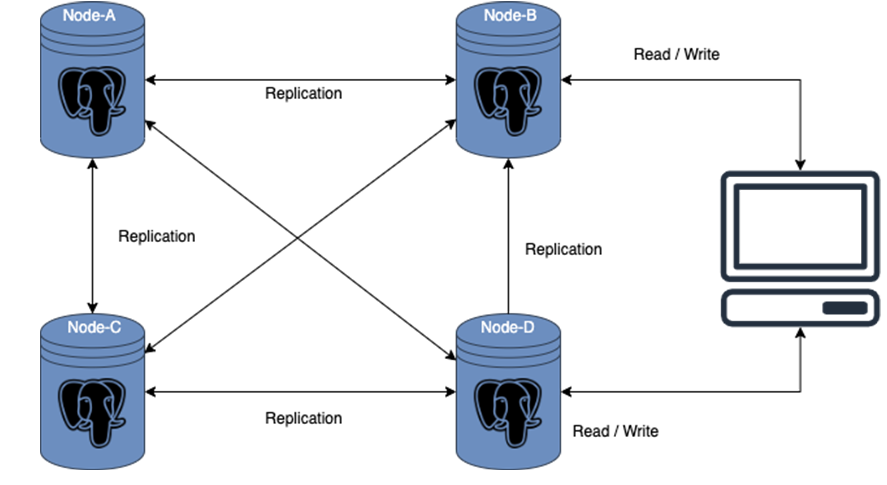

Ngoài ra có một cơ chết trung chuyển dữ liệu từ node nọ sang node kia khi bạn thêm hoặc bớt node, nó được gọi là Rebalancer.
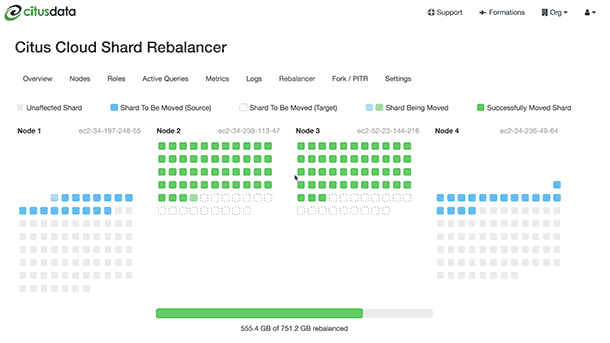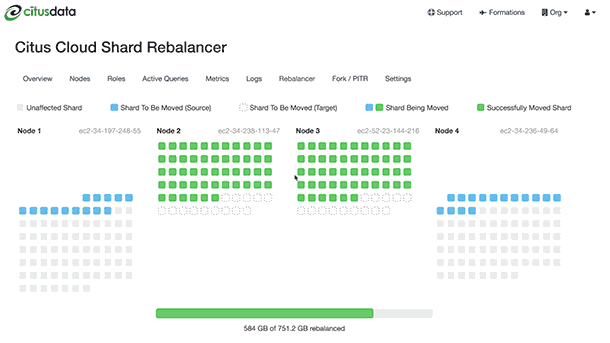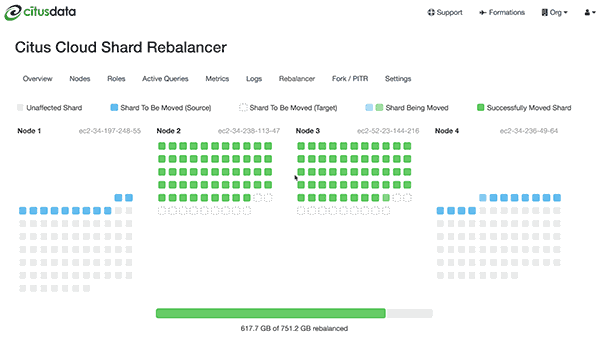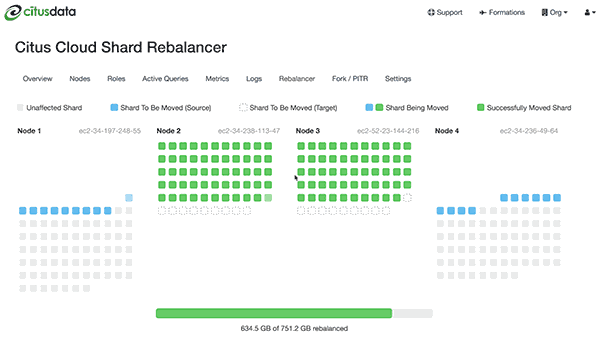
Đến đây vấn đề lại phát sinh khi bạn muốn chia như thế nào, chia cơ sở dữ liệu theo chiều dọc hay theo chiều ngang. Hãy nhìn ví dụ cách chia một bảng dữ liệu sau
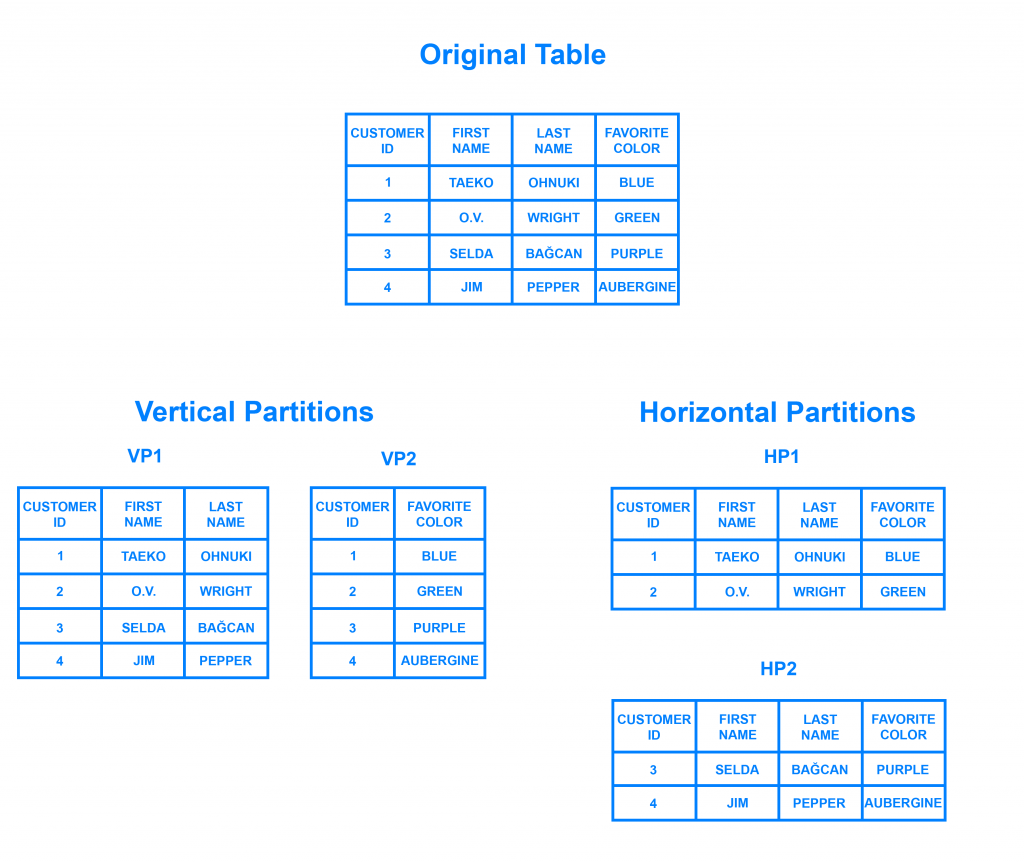
Khi bạn chia theo chiều dọc thì giống như việc bạn cắt từng cột từng cột bỏ trên từng node và liên kết chúng lại thông qua khóa chính chung. Nhưng thực tế rằng dữ liệu luôn có quan hệ với nhau, khó lòng mà có thể chia cắt dữ diệu kiểu này, nhất là mô hình data-driven applications (thiết kế ứng dụng hướng dữ liệu)
Và cách chia cắt dữ liệu cho các node theo chiều ngang như trên chính là Sharding mà mình muốn đề cập tới.
A database shard, or simply a shard, is a horizontal partition of data in a database or search engine. Each shard is held on a separate database server instance, to spread load.
Sharding is a database architecture pattern related to horizontal partitioning — the practice of separating one table’s rows into multiple different tables, known as partitions. Each partition has the same schema and columns, but also entirely different rows. Likewise, the data held in each is unique and independent of the data held in other partitions.
Đến đây có lẽ bạn đã hiểu việc tại sao lại phải chia tách cơ sở dữ liệu cũng như sharding là gì rồi!Giờ thì cùng mình tìm hiểu tiếp ưu và nhược điểm của sharding database nhé
Ưu điểm:
– Việc chia tách thành các node với những cơ sở dữ liệu nhỏ thì đương nhiên ưu điểm chính là việc cải thiện băng thông và tốc độ truy vấn rồi. Điều này là hiển nhiên khi bạn cho phép nhiều hơn lượng traffic cũng như tốc độ thông qua. Bạn mở một con đường mới 8 làn nó khác với một con đường làng chỉ có xe máy vào được.
– Có lẽ bạn từng nhớ tới phương pháp chia để trị mà mình đã nói đến ở bài viết trước, bạn có thểm xem lại tại đây:
# http://blog.ntechdevelopers.com/chia-de-tri-xu-huong-phan-tan-mot-xu-huong-di-dau-cung-gap/
Phương pháp này cũng được áp dụng để tăng hiệu suất với sharding, bạn chia khối lượng công việc của bạn và thực hiện chúng một cách song song sẽ khiến bạn có thời gian hoàn thành xử lý công việc nhanh hơn.
– Một điểm nữa mà việc chia tách dữ liệu thành các node trở thành ưu điểm đó chính là xử lý lỗi, khi có vấn đề xảy ra với một node, bạn chỉ bị vấn đề của một phần dữ liệu trên node đó, và lập tức có một cơ chết roll over kết hợp với rebalancer giúp bạn xử lý được sự cố một cách nhanh chóng. Quay trở lại ví dụ từng đoạn dây ngắn nối dài, khi một đoạn dây bị sờn sắp đứt thì bạn chỉ việc tháo đoạn dây đó ra và thay thế bằng đoạn dây khác mà không làm ảnh hưởng tới các đoạn dây còn lại.
Nhược điểm:
Nhiều ưu điểm là thế nhưng Sharding cũng có khá nhiều nhược điểm đáng lưu tâm khi bạn sử dụng đó.
– Thứ nhất là việc sharding lợi cho việc truy vấn nhưng vấn đề merge và sort dữ liệu thì nó lại là một vấn đề cần phải xử lý đó. Bạn hình dung một đoạn dây dài của bạn với nhiều đoạn đây nhỏ, tuy nhiên bạn lại có thứ tự trong những đoạn dây nhỏ, thì việc đổi chỗ và sắp xếp chúng thì sẽ ảnh hưởng đến toàn bộ đoạn dây, trật tự dữ liệu nằm rải rác khiến việc sắp xếp chúng lại là một công đoạn khó khăn và mất nhiều thời gian hơn nếu bạn xử lý không tốt.
– Thứ hai là tiến trình sharding là một công đoạn rất phức tạp, không dễ gì một người mới có thể tiếp cận. Ví dụ trong dự án của bạn đã thực hiện mô hình distributed database và đánh shard các bảng các cột trong của dự án thì bạn là một người mới, bạn tiếp cận những logic sharding trước đó là một điều gian nan và thử thách đó, chưa kể khi bạn tiếp cận một yêu cầu mới cần chia tách và sharding lại dữ liệu thì dường như bạn sẽ chẳng biết bắt đầu từ đâu.
– Vấn đề tiếp theo là các issue phát sinh từ Sharding cũng như Citus rất nhiều. Khá đau đầu khi bạn phải xử lý những business logic mà bạn chẳng hiểu tại sao nó lại sai. Ví dụ khi bạn muốn lấy một thông tin cá nhân của khách hàng, được đánh shard với customer_id nhưng bạn không xác định được dữ liệu đó đang nằm trên node nào và được liên kết dữ liệu các node ra sao. Bạn vẫn truy vấn, nó không có lỗi gì xảy ra, nó chỉ không tìm thấy mà thôi. Đó chỉ là một ví dụ đơn giản trong vô số vấn đề mà mình gặp phải. Mình sẽ có một bài viết riêng cho những vấn đề từng gặp của mình đối với Citus sau.
– Cùng với vấn đề những problems phát sinh khi sử dụng sharding còn gặp rất nhiều khó khăn với những câu truy vấn, nhất là khi bạn sinh những câu truy vấn T-SQL từ code tầng trên như C# để có thể truy vấn. Khi này bạn phải cân nhắc không có những câu truy vấn phức tạp với dữ liệu trên nhiều node. Ví dụ bạn cần dữ liệu A liên kết với dữ liệu B, có được kết quả C rồi liên kết tiếp với dữ liệu D có chứa điều kiện E. Điều này rất khó khăn khi các dữ liệu cảu bạn bị phân tán rồi, bạn không thể viết một mạch như kiểu chúng nằm trên cùng một database. Thay vào đó bạn phải truy vấn lẻ từng dữ kiện và kết hợp chúng lại. Điều này gây khó khăn trong quá trình phát triển phần mềm. Hơn nữa thì khá năng tương thích khi thay đổi yêu cầu hoặc tiếp nhận một yêu cầu mới trong nghiệp vụ của bạn sẽ khó khăn. Tính khả dụng và tương thích trong ứng dụng lúc này của bạn sẽ gặp vấn đề.
Bài viết khá dài rồi, bài viết sau mình sẽ chia sẻ làm thế nào bạn có thể sử dụng sharding trong citus data.
Hi vọng các bạn có quan tâm và đón đọc!

[…] ← Previous […]
[…] Hiểu về Sharding trong Citus Data […]