 và câu chuyện tăng hiệu năng")
Citus data (cơ sở dữ liệu phân tán) và câu chuyện tăng hiệu năng
November 28, 2020Nếu bạn đang tìm kiếm giải pháp để có thể scale out (mở rộng) các thành phần thuê dịch vụ (multi-tenant) hay bạn muốn xây dựng một bảng điều khiển phân tích thời gian thực, thứ mà giúp cho khách hàng của bạn có thể truy vấn và phân tích với tốc độ hiệu năng rất cao, hàng tỉ rows (hàng) dữ liệu. Điều đáng đề cập ở đây là scale out theo chiều ngang (horizontally) thay vì theo chiều dọc (vertically) như truyền thống.
Đọc cái mở đầu đã chẳng hiểu gì rồi!
Cùng đi từng định nghĩa một nhé. Mình sẽ lấy theo ví dụ giúp bạn tưởng tượng hình dung dễ dàng hơn.
Đầu tiên là siêu mở rộng (Hyperscale), vấn đề mở rộng cơ sở dữ liệu cũng như hạ tầng trong phát triển phần mềm dường như là khá quan trọng. Chẳng ai muốn viết một phần mềm mà nó chỉ đáp ứng được nhu cầu hiện tại trong khi công nghệ nhu cầu mỗi lúc một tăng. Điều mở rộng và khả năng tương thích để mở rộng là điều cần thiết trong phát triển phần mềm. Nhưng thứ mà bạn xây dựng và phát triển cách đây 10 năm, 20 năm làm sao bạn biết được nhu cầu tương lai như thế nào để có thể chuẩn bị sẵn sàng cho mở rộng. Điều bạn quan tâm ở đây chỉ là làm sao để tương thích với mở rộng đó dễ dàng và tốn ít chi phí nhất có thể.
Ví dụ, bạn mới xây dựng một trang web với sức chứa của cơ sở dữ liệu lưu đủ 1 triệu người dùng, điều gì sẽ xảy ra khi website của bạn quá hot và nó lên đến cả tỉ người dùng vào sau thời điểm phát hành 1 tuần sau đó. Tất nhiên là bạn nâng cơ sở hạ tầng từ 1GB dung lượng lên 10GB dung lượng rồi. Nhưng mà đời đâu như là mơ, khi chỉ nâng dung lượng như thế, khi bạn truy vấn lấy dữ liệu của một người dùng, bạn phải tìm kiếm trong 1 tỉ người dùng khác để có thể tìm thấy dữ liệu của bạn. Cái thời gian truy vấn đó bạn hình dung sẽ mất bao lâu đây? Chưa kể Ram, CPU xử lý cho hàng tỉ người dùng đó sẽ tăng theo, thập chí sập luôn cả hệ thống. Bạn có muốn vì những người dùng mới mà làm ảnh hưởng đến tập người dùng cũ đang hái ra tiền ở thời điểm hiện tại không?
Việc mở rộng phải nhanh, đáp ứng tốt, vận hành, cấu hình, quản lý dễ dàng. Khi đó thuật ngữ siêu mở rộng Hyperscale ra đời.
Tiếp đó là thuật ngữ worry-free và worry-free Postgres. Mình cũng không biết dịch từ worry-free ra tiếng việt là gì nữa, sự thảnh thơi chăng@@
Hay như câu sologan của Postgres (một cơ sở dữ liệu quan hệ dối tượng) “Never Worry About Scaling Your Database Again”. Đúng là hay thật, bạn sẽ không bao giờ lo lắng về vấn đề mở rộng cơ sở dữ liệu một lần nào nữa. Có lẽ từ worry-free xuất phát từ đây, giúp hệ thống thảnh thơi nhàn hạ, dễ dàng mở rộng, dễ dàng vận hành.
Một thuật ngữ mà gắn liền với sự mở rộng hệ thống đó là Cluster. Clustering chính là 1 kiến trúc được tạo ra với mục đích đảm bảo nâng cao khả năng sẵn sàng cho những hệ thống mạng. Clustering bao gồm những server riêng lẻ được kết nối với nhau đồng thời hoạt động lại cùng nhau trong 1 hệ thống. Những server này giao tiếp với nhau với mục đích trao đổi thông tin và giao tiếp với cả những mạng bên ngoài để thực hiện những yêu cầu. Trong trường hợp có lỗi xảy ra những dịch vụ trong cluster hoạt động tương tác với nhau để duy trì tính ổn định và độ sẵn sàng cao cho hệ thống.
Được rồi! Đi vào định nghĩa Citus, nó là một thứ dựa trên worry-free Postgres giúp bạn có thể mở rộng cơ sở dữ liệu. Nó là sự phát triển mở rộng của cơ sở dữ liệu phân tán trong Postgres, bên cạnh việc truy vấn trong một cluster của một máy. Citus chỉ hỗ trợ PostgreSQL tại thời điểm hiện tại, nên nếu hệ thống của bạn đang sử dụng hệ cơ sở dữ liệu quan hệ này thì có thể cân nhắc lợi ích của việc sử dụng citus.
Lại khó hiểu rồi, vậy cơ sở dữ liệu phân tán là gì?
Hiểu đơn giản là bạn lưu dữ liệu ở nhiều nơi, mỗi nơi một ít. Ví dụ, bạn có một bảng lưu thông tin người khách hàng gồm (mã khách hàng, họ, tên, màu sắc khách hàng đó yêu thích). Theo nguyên tắc một khối monolithic thì nó sẽ lưu hết tại một máy chủ chửa cả 4 thông tin trên. Khi bạn truy vấn lấy khách hàng mã thứ nhất thì cứ thế lấy ra thôi. Nhưng vấn đề là có 1 tỉ khách hàng ban đầu mình đề cập thì hệ thống của bạn phải tìm kiếm hàng triệu dữ liệu của khách hàng khách trong cùng một bảng. Còn một vấn đề thứ hai là bạn chỉ muốn lấy thông tin của màu sắc khách hàng bạn yêu thích thôi. Bạn không quan tâm đến họ, tên khách hàng đó.
Khi đó bài toán đặt ra là chia dữ liệu của bạn làm sao để tối ưu thời gian truy vấn lấy lên được.
Có 2 cách chia:
– Bạn chia theo mã khách hàng, từ mã 1 đến mã 100 thì lưu ở máy thứ nhất, từ 100 đến 200 chia ở máy thứ 2,… Mình nói máy cho dễ hiểu thôi nhưng thực tế là trên node, một máy có thể xây dựng nhiều cluster, một cluster có thể xây dựng nhiều node (server). Đến khi bạn muốn lấy dữ liệu mã thứ 5 bạn chỉ việc vào node 1 truy vấn thôi. Dễ hiểu đúng không! Đây được gọi là chia cơ sở dữ liệu phân tán theo chiều ngang.
– Bạn để trường họ, tên ở máy thứ nhất hoặc node thứ nhất, bạn để trường màu sắc yêu thích ở máy thứ hai. Khi bạn chỉ muốn lấy dữ liệu màu sắc yêu thích của khách hàng thì bạn chỉ vào máy thứ 2 bạn lấy mà thôi. Đây được gọi là chia cơ sở dữ liệu phân tán theo chiều dọc
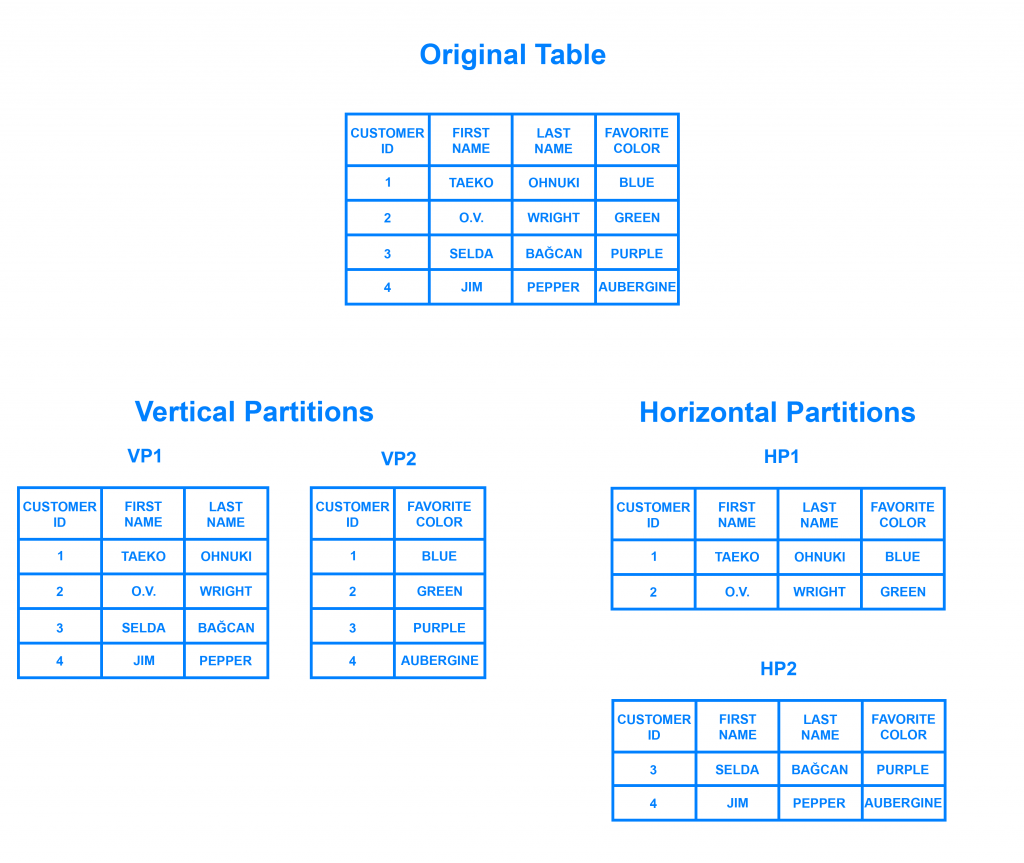
Quay trở lại vấn đề Citus, thì Citus là dạng mở rộng cơ sở dữ liệu phân tán của cơ sở dữ liệu quan hệ PostgreSQL theo chiều ngang. Bên cạnh đó nó thực thi truy vấn song song (bất đồng bộ) một cách mà họ coi là real-time (ngay lập tức) chỉ mất nhỏ hơn một giây đối với dữ liệu lớn.
Có 3 điều mà Citus luôn sẵn sàng đáp ứng đó là:
– Nó là mã nguồn mở và được nằm ngay trong Postgres server
– Nó có hỗ trợ công cụ quản lý bảo mật (security) và quản lý cluster.
– Nó sẵn sàng build trên cloud (đám mây) của Azure và AWS (tuy rằng AWS không còn hỗ trợ những người dùng mới nữa)
Tiếp theo là Citus sử dụng 2 kỹ thuật sharding và replication.
– Sharding là một mẫu kiến trúc cơ sở dữ liệu liên quan tới chia cắt theo chiều ngang. Nó chia bảng gốc thành nhiều bảng khác nhau, mỗi bảng sẽ giống nhau về schema(lược đồ) và columns(tất cả các cột). Bên cạch đó, nó còn có một cột nhắm liên kết và tìm kiếm dữ liệu liên quan, chẳng hạn như mã khách hàng ở ví dụ bên trên. Điều quan trọng là cột liên kết này phải là duy nhất và không được thay đổi.
– Replication là một bộ các giải pháp cho phép sao chép và phân phối cơ sở dữ liệu giữa các server và đồng bộ chúng nhằm duy trì tính nhất quán dữ liệu. Nó là giải pháp được ứng dụng cho môi trường phân phối dữ liệu trên nhiều server
Bài viết sau mình sẽ đi tiếp vào việc tại sao và khi nào thì nên dùng Citus. Cám ơn các bạn đã theo dõi!

[…] Lại tiếp tục với Citus Data và cơ sở dữ liệu phân tán, như bài viết trước thì có lẽ các bạn đã mường tượng ra được cái Citus data là gì rồi nhỉ, nếu chưa thì bạn có thể đọc lại tại# http://blog.ntechdevelopers.com/citus-data-va-cau-chuyen-tang-hieu-nang-phan-1/ […]
[…] Citus data (cơ sở dữ liệu phân tán) và câu chuyện tăng hiệu năng […]