
Giới thiệu về CQRS
July 10, 2021Cùng mình đặt vấn đề một chút với ví dụ sau đây, một cửa hàng bách hóa, muốn nhập các đồ hàng để bán cho khách hàng, họ chỉ có duy nhất một kho chứa hàng, khi họ bán hết hàng, họ dành một ngày nghỉ bán để nhập hàng đầy kho, và hôm sau họ mới tiếp tục có thể bán được vì kho hàng của họ chỉ có một lối vận chuyển dữ liệu cũng như lối để khách hàng vào xem hàng, họ không thể đặt một cái ô tô cả ngày chắn lối khách hàng vào mua được. Đó là lý do họ phải nghỉ bán để nhập hàng và ngược lại, nghỉ nhập hàng để bán.
Với ví dụ này bạn thử liên tưởng tới một ứng dụng website thử, một phần mềm thường giống như việc nhập hàng và bán hàng vậy, nhập hàng như phần thêm/xóa/sửa dữ liệu (dữ liệu ở đây là cái mà khách hàng có thể thấy trên website ví dụ như là hình ảnh, âm thanh, bài viết, video…), bán hàng thì giống như phần xem dữ liệu như thứ bạn đang đọc ở đây.
Vấn đề được đặt ra là tài nguyên của trang web của bạn có hạn (dung lượng, bộ nhớ, băng thông…) cũng như kho chứa hàng của bạn có diện tích có hạn, việc bạn nhập và xuất hàng đều bị ảnh hưởng đến nhau, và bạn thì chẳng hề muốn khách hàng phải chờ đúng không nào.
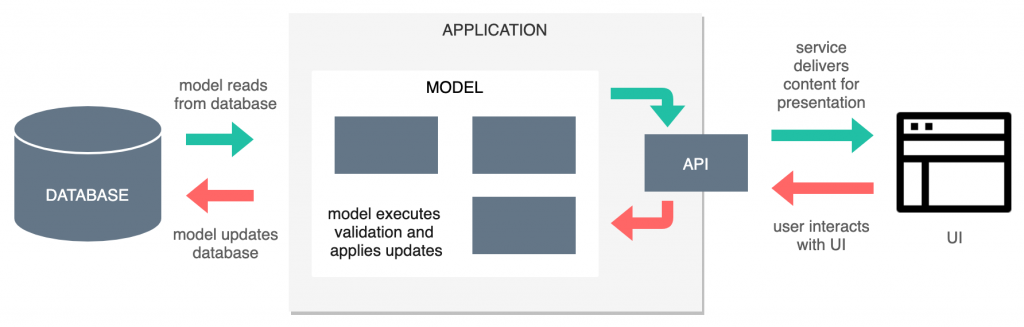
Trước đó, bạn có thể nghe nhìn ở đâu đó cụm từ CRUD, nó chính là viết tắt của Create, Read, Update, Delete một dữ liệu. Ừ thì đương nhiên 4 chức năng này độc lập nhưng không phải là bạn chỉ có một cái cổng để nhập và xuất hàng sao, nghĩ là chúng đang chia sẻ tài nguyên và có thể ảnh hưởng đến nhau. Từ vấn đề này thì vài năm trở lại đây nở rộ ra một mô hình chính là CQRS.
Vậy CQRS thực sự là gì?
Một định nghĩa đơn giản về CQRS, nó là viết tắt của Command and Query Responsibility Segregation, một mẫu thiết kế (pattern) giúp bạn chia tách hệ thống đọc và ghi ra thành 2 luồng riêng biệt khi làm việc với kho dữ liệu.
Đọc và ghi có lẽ là 2 luồng cơ bản nhất để có thể trao đổi một thực thể dữ liệu từ một tầng ứng dụng đến tầng cơ sở dữ liệu. Vậy là CRUD mình có thể chia thành 2 nhóm đó là Command (Create, Update, Delete) và Query (Read).
Bạn hỏi tại sao CRUD cũng được mà tại sao lại sinh ra mô hình mới chi phức tạp vậy. Cũng như ví dụ ở trên, một kho hàng sẽ hoạt động hiệu quả hơn nếu mình mở 2 cánh cửa trước và sau cửa hàng, một cửa chuyên để khách hàng tới mua sắm tùy thích, một cửa chuyên để dành cho các xe vận tại chuyển hàng nhập kho, việc nhập hàng vào kho sẽ không hề bị ảnh hưởng tới khách mua hàng, nhân viên nhập hàng cũng chẳng ảnh hưởng đến nhân viên sale hay lễ tân tiếp khách.
Ứng dụng ở đây cũng vậy sự phân tách I/O (Input/Output) giúp cho chúng không ảnh hưởng đến nhau.
Ngoài ra còn một lý do nữa mà khiến các nhà phát triển ưa chuộng mô hình này, đó là tùy thuộc vào nhu cầu sử dụng của tập khách hàng mà họ có thể điều chỉnh tài nguyên sao cho phù hợp. Ví dụ một trang web như spiderum bạn nghĩ có bao nhiêu tác giả viết bài và có bao nhiêu độc giả đọc bài. Tất nhiên là số lượng độc giả gấp cả trăm lần tác giả, vậy bạn nên xây dựng cổng ưu tiên cho độc giả vào hơn hay là ưu tiên cho tác giả hơn. Ở đây mình không đánh giá về mức độ quan trọng của độc giả và tác giả, mình muốn nhấn mạnh một điều là về thời gian truy xuất dữ liệu của độc giả sẽ nhiều hơn thời gian đăng bài của tác giả, vậy không lý nào xây cửa cho độc giả lại nhỏ hơn, nó sẽ dẫn tới hiện tượng gọi là nghẽn cổ chai (bottleneck)
Một ví dụ nữa là việc ưu tiên theo thời gian truy cập của khách hàng, facebook thì bạn thường đăng story vào những lúc rảnh rỗi, giờ nghỉ ngơi, trong khi thời gian còn lại thì bạn chỉ lướt lướt đọc newfeeds. Vậy nếu là bạn thì bạn sẽ mở cửa nào rộng hơn vào thời gian nào. Về thực tế thì chúng không cùng cơ sở dữ liệu (database) đâu, họ sẽ chọn một sơ sở dữ liệu thiên về truy vấn nhanh như noSQL để làm cơ sở dữ liệu đọc, và một cơ sở ràng buộc dữ liệu chặt chẽ như Oracle hay SQL server để lưu khi đăng bài. Chúng sẽ có cơ chế đồng bộ phía sau và chạy ngầm bên dưới thông qua những event (sự kiện) và mạng lưới message bus (mạng lưới truyền nhận tín hiệu bất đồng bộ)
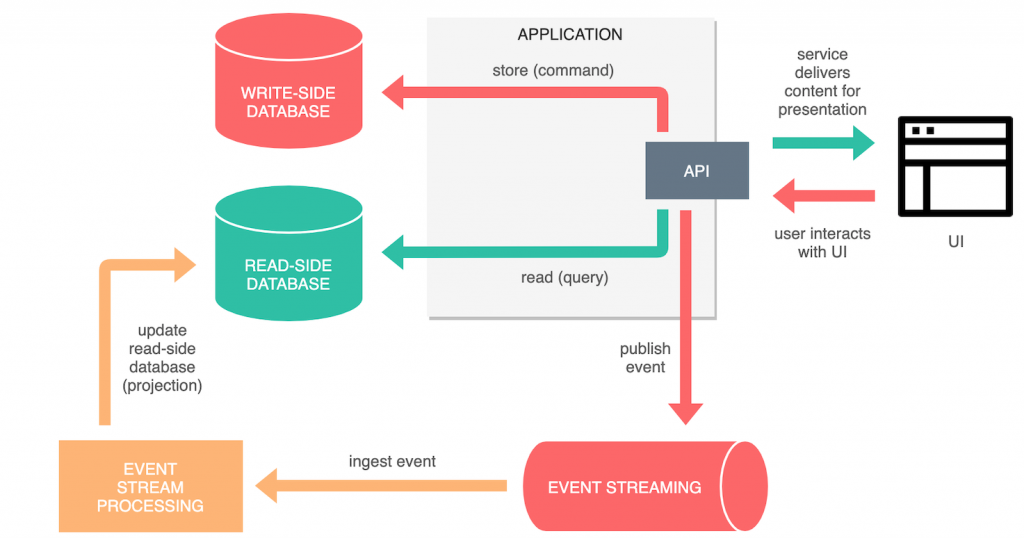
Vậy tổng kết lại thì CQRS có những lợi ích gì?
Facilitates distributing dev workload: Việc chia đội ngũ phát triển ra thành 2 phần, tôi đảm nhận việc lưu dữ liệu vào sẽ không cản trở việc anh lấy dữ liệu ra, và tôi và anh có thể làm việc song song, độc lập với nhau cũng như nhân viêc nhập kho hàng không ảnh hưởng đến nhân viên bán hàng. Với những việc khó và cần nhiều người như nhân viên bán hàng thì tôi là quản lý tôi sẽ tuyển đông nhân viên bán hàng hơn là nhân viên nhập kho.
Easier maintenance: Dễ dàng bảo trì bảo dưỡng hệ thống, điều này chắc những ai chuyên đi sửa lỗi dạo, fix bug thuê sẽ hiểu được, khi mà đọc logic lưu xuống mà dính với lấy ra tính toán phức tạp thì mất rất nhiều thời gian. Khi mà tôi kiểm tra cơ sở dữ liệu đúng thì tôi biết luống lưu xuống của tôi không bị lỗi thay vào đó luồng tính toán lấy lên của tôi bị sai, việc khoanh vùng lỗi cũng dễ dàng hơn.
Optimized database design: Đọc ra đọc mà ghi ra ghi, khi cơ sở dữ liệu hệ thống của tôi ưu tiên việc truy xuất dữ liệu sao cho nhanh nhất có thể thì tôi sẽ thiết kế hệ thống tìm kiếm (elastic search), sắp xếp (sorting), đánh chỉ mục (indexing), chia cụm dữ liệu (sharding)… Nếu mà bạn có nghe ở đâu đó một cấu trúc dữ liệu nào giúp bạn tìm kiếm nhanh nhưng mà cập nhập lại chậm thì bạn có thể biết tới Linked List. Vì đơn giản là chúng sắp xếp liên kết với nhau để tối ưu việc tìm kiếm, nhưng mỗi lần thêm vào thì chúng lại phải đi tìm con trỏ để xác định đúng vị trí thì mới thêm vào. Vậy tại sao ý tưởng này không được thiết kế tự đầu để tối ưu cơ sở dữ liệu chứ!
Easier scalability: Như mình đã đề cập bên trên, việc xây cửa rộng hay hẹp để tôi ưu việc đọc và ghi dữ liệu khá là dễ dàng tôi biết được thời gian nào đông khách tôi sẽ mở rộng cửa thu ngân, khi nào ít khách hết hàng thì tôi mở rộng cửa kho. CQRS cũng vậy, chúng giúp cho việc mở rộng và sử dụng tài nguyên một cách linh hoạt hơn.
Enhanced security: Ngày nay thì có lẽ bất cứ công nghệ nào cũng đang chú trọng tới bảo mật thông tin, việc chia luồng dữ liệu đọc ghi này có thể giúp bạn phân loại người dùng và hạn chế quyền của họ sao cho đúng đắn nhất. Một nhân viên sale sẽ không bao giờ có quyền nhập liệu hàng vào kho.
Có vẻ tốt đấy nhỉ, nhưng nó không phải không có mặt trái nhé!
Đầu tiên là làm phức tạp hóa vấn đề, thường thì khi thêm mới, tôi sẽ trả về luôn dữ liệu vừa thêm. Ở đây chính vì sự tách biệt giữa đọc và ghi nên khi thêm mới xong tôi không trả về ngay mà tôi gửi một tin hiệu khác cho luồng xử lý đọc làm việc tiếp, rồi khi tín hiệu đó bị gián đoạn thì xử lý tiếp ra sao, ôi thật là phức tạp làm sao.
Thứ hai đó là tính nhất quán dữ liệu, luồng đọc và ghi không làm việc cùng nhau nên có thể bài viết bạn vừa đăng phải vài giây sau nó mới xuất hiện trên trang cá nhân của bạn, vậy bạn nghĩ sao khi bạn vừa đăng bài và treo mạng khiến bạn click liên tục nút đăng, một lát sau có cả chục bài đăng giống nhau load lên tường nhà bạn. Nguyên nhân là tín hiệu nhận được đọc và ghi nó hoàn toán đọc lập và nó chỉ nhận tín hiệu thông qua event hay message mà thôi. Hay như cơ sở dữ liệu lưu vào khác với cơ sở dữ liệu lấy ra, chúng phải chờ để được đồng bộ dữ liệu.
Lợi có, hại cũng có, vậy khi nào thì sử dụng CQRS?
Đầu tiên là bạn ưu tiên hệ thống đọc hơn là ghi.
Chia team phát triển tập trung chỉ xử lý dữ liệu đọc, và một team chỉ xử lý dữ liệu ghi nếu business phức tạp.
Cuối cùng là một số trường hợp ghi nhiều hơn đọc ví dụ như giao dịch ngân hàng thì hằng ngày, nhưng báo cáo sao kê thì cả tháng mới có một lần.
Vậy CQRS và CRUD thì cái nào tốt hơn?
Thật là khó trả lời cho câu hỏi này. Thường thì nó phụ thuộc vào những yếu tố và trường hợp sau đây:
– Độ khó của logic nghiệp vụ
– Độ lớn của tổ chức hệ thống
– Độ ưu tiên và sự cần thiết của hiệu suất đọc hay ghi
– Ứng dụng có đang áp dụng kiến trúc Event-Driven hay không? (Kiến trúc này mình sẽ giới thiệu ở một bài viết khác sau nhé)
Bài viết trên đây giúp bạn hiểu được CQRS là gì cũng như ưu và nhược điểm của nó, khi nào thì sử dụng CQRS hay CRUD. Bài viết sau mình sẽ nói rõ hơn về cách xây dựng mô hình này với ngôn ngữ C#. Hi vọng có thể giúp ích được cho các bạn.

[…] – CQRS + https://blog.ntechdevelopers.com/gioi-thieu-ve-cqrs/ + https://blog.ntechdevelopers.com/step-by-step-implements-cqrs-in-microservice/ [SOLID] […]